Introduction
Every disk crash is different. The point being a disk crash should never happen, so when it does, the results and probability of recovery is highly variable.
This is the story of a Proxmox server which had 6 disks and a hardware RAID card:
- Disks 1 to 3, NVMe, tied to the hardware card. RAID5 for added performance
- Disks 5 and 6, tied to the hardware card. RAID1 mirror.
- Disk 6. Single “throwaway” drive. No redundancy.
The idea was to use Disk 6 for “throwaway” with no key loads. Disk space in general was expensive and at a premium, so it made sense to conserve as much as possible in other places. Backing up VMs is highly dynamic and disk 6 was going to be the experiment.
The problem with Proxmox’s VM storage is it’s just not your normal file system any more. Although it’s Debian, it’s not just EXT4. It’s not just LVM. It has added layers which you have to understand before you can do disk recovery. Disk recovery is already hard, so without some insight into these layers, or the tools needed to fix the underlying disk, you’re pretty screwed.
The new commands during this procedure, which we typically don’t use from day to day, are:
- vgchange
- lvchange
It all started like this:
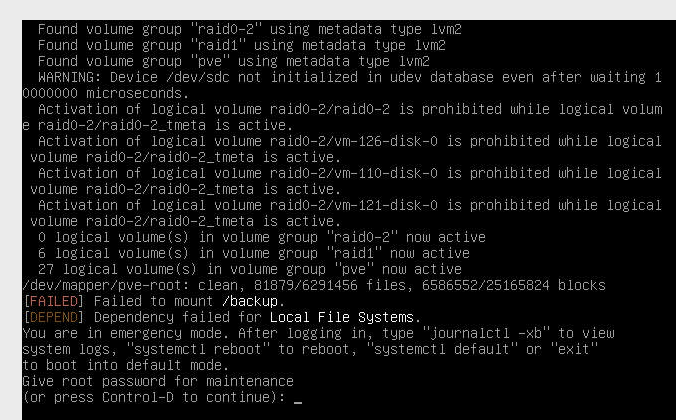
Fortunately, because the disk was mounted in /etc/fstab, I could quickly start up the server again, bringing up all the other VMs.
# cat /etc/fstab # <file system> <mount point> <type> <options> <dump> <pass> /dev/pve/root / ext4 errors=remount-ro 0 1 /dev/pve/swap none swap sw 0 0 proc /proc proc defaults 0 0 #/dev/sdc /backup ext4 defaults 0 0
However, I found this message repeating in the log file:
Apr 27 18:57:16 hv7 pvestatd[1580]: activating LV 'raid0-2/raid0-2' failed: Activation of logical volume raid0-2/raid0-2 is prohibited while logical volume raid0-2/raid0-2_tmeta is active.
Only much later I realized you have to look super close, as the end _tmeta is important (there is a _tdata also).
The first command I was told to run was this, which display something similar. This vgchange -ay` command is actually very useful because we can see three VM disks affected by the crash:
# vgchange -ay Activation of logical volume raid0-2/raid0-2 is prohibited while logical volume raid0-2/raid0-2_tmeta is active. Activation of logical volume raid0-2/vm-126-disk-0 is prohibited while logical volume raid0-2/raid0-2_tmeta is active. Activation of logical volume raid0-2/vm-110-disk-0 is prohibited while logical volume raid0-2/raid0-2_tmeta is active. Activation of logical volume raid0-2/vm-121-disk-0 is prohibited while logical volume raid0-2/raid0-2_tmeta is active. 0 logical volume(s) in volume group "raid0-2" now active 6 logical volume(s) in volume group "raid1" now active 27 logical volume(s) in volume group "pve" now active
Next Googling this problem is excruciating hard. Disks just don’t crash that often and it’s a really specialized art. The next command I was told to run is this lsblk.
As you can see from the output below, the /dev/sdc crashed disk looks different:
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 1.7T 0 disk ├─sda1 8:1 0 1007K 0 part ├─sda2 8:2 0 512M 0 part └─sda3 8:3 0 1.7T 0 part ├─pve-swap 253:0 0 8G 0 lvm [SWAP] ├─pve-root 253:1 0 96G 0 lvm / ├─pve-data_tmeta 253:2 0 15.8G 0 lvm │ └─pve-data-tpool 253:15 0 1.6T 0 lvm │ ├─pve-data 253:16 0 1.6T 1 lvm <snip VMs> └─pve-data_tdata 253:3 0 1.6T 0 lvm └─pve-data-tpool 253:15 0 1.6T 0 lvm ├─pve-data 253:16 0 1.6T 1 lvm <snip VMs> sdb 8:16 0 3.6T 0 disk ├─raid1-raid1_tmeta 253:6 0 120M 0 lvm │ └─raid1-raid1-tpool 253:8 0 3.6T 0 lvm │ ├─raid1-raid1 253:9 0 3.6T 1 lvm <snip VMs> └─raid1-raid1_tdata 253:7 0 3.6T 0 lvm └─raid1-raid1-tpool 253:8 0 3.6T 0 lvm ├─raid1-raid1 253:9 0 3.6T 1 lvm <snip VMs> sdc 8:32 0 3.6T 0 disk ├─raid0--2-raid0--2_tmeta 253:4 0 15.8G 0 lvm └─raid0--2-raid0--2_tdata 253:5 0 3.6T 0 lvm
But we had these repeating message in the log and were told to use lvchange. This article really helped:
https://talhamangarah.com/blog/proxmox-7-activating-lvm-volumes-after-failure-to-attach-on-boot/
Finally we got the syntax right:
root@hvX:~# lvchange -an raid0-2/raid0-2_tdata
Now we see in the log file that tmeta becomes tdata:
root@hvX:~# tail -f /var/log/syslog Apr 27 19:11:46 hvX pvestatd[1580]: activating LV 'raid0-2/raid0-2' failed: Activation of logical volume raid0-2/raid0-2 is prohibited while logical volume raid0-2/raid0-2_tmeta is active. <snip repeat> Apr 27 19:13:25 hvX pvestatd[1580]: activating LV 'raid0-2/raid0-2' failed: Activation of logical volume raid0-2/raid0-2 is prohibited while logical volume raid0-2/raid0-2_tdata is active.
Next we do the same:
root@hvX:~# lvchange -an raid0-2/raid0-2_tdata root@hvX:~# tail -f /var/log/syslog Apr 27 19:17:57 hvX pvedaemon[1604]: activating LV 'raid0-2/raid0-2' failed: Activation of logical volume raid0-2/raid0-2 is prohibited while logical volume raid0-2/raid0-2_tdata is active. Apr 27 19:18:09 hvX pvedaemon[1604]: activating LV 'raid0-2/raid0-2' failed: Activation of logical volume raid0-2/raid0-2 is prohibited while logical volume raid0-2/raid0-2_tdata is active.
Now lsblk looks more in line with the rest of the disks:
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 1.7T 0 disk ├─sda1 8:1 0 1007K 0 part ├─sda2 8:2 0 512M 0 part └─sda3 8:3 0 1.7T 0 part ├─pve-swap 253:0 0 8G 0 lvm [SWAP] ├─pve-root 253:1 0 96G 0 lvm / ├─pve-data_tmeta 253:2 0 15.8G 0 lvm │ └─pve-data-tpool 253:15 0 1.6T 0 lvm │ ├─pve-data 253:16 0 1.6T 1 lvm <snip VMs> └─pve-data_tdata 253:3 0 1.6T 0 lvm └─pve-data-tpool 253:15 0 1.6T 0 lvm ├─pve-data 253:16 0 1.6T 1 lvm <snip VMs> sdb 8:16 0 3.6T 0 disk ├─raid1-raid1_tmeta 253:6 0 120M 0 lvm │ └─raid1-raid1-tpool 253:8 0 3.6T 0 lvm │ ├─raid1-raid1 253:9 0 3.6T 1 lvm <snip VMs> └─raid1-raid1_tdata 253:7 0 3.6T 0 lvm └─raid1-raid1-tpool 253:8 0 3.6T 0 lvm ├─raid1-raid1 253:9 0 3.6T 1 lvm <snip VMs> sdc 8:32 0 3.6T 0 disk ├─raid0--2-raid0--2_tmeta 253:4 0 15.8G 0 lvm │ └─raid0--2-raid0--2-tpool 253:41 0 3.6T 0 lvm │ ├─raid0--2-raid0--2 253:42 0 3.6T 1 lvm │ └─raid0--2-vm--110--disk--0 253:43 0 150G 0 lvm └─raid0--2-raid0--2_tdata 253:5 0 3.6T 0 lvm └─raid0--2-raid0--2-tpool 253:41 0 3.6T 0 lvm ├─raid0--2-raid0--2 253:42 0 3.6T 1 lvm └─raid0--2-vm--110--disk--0 253:43 0 150G 0 lvm
After running the command for _tmeta and _tdata we got this:
# vgchange -ay 4 logical volume(s) in volume group "raid0-2" now active 6 logical volume(s) in volume group "raid1" now active 27 logical volume(s) in volume group "pve" now active
Yay! After that, I could start VMs again 
Question? Was that mount command a possible issue? Please comment if you have advice.
Other articles referencing this problem:
This reddit article referred to the main article referenced in this article:
https://www.reddit.com/r/Proxmox/comments/tamokn/cant_run_pve_at_all_task_error_activating_lv/
Fiona of Proxmox tries to explain this problem in detail here:
Other users experiencing this problem:
- https://forum.proxmox.com/threads/error-activating-lv.113888/
- https://forum.proxmox.com/threads/task-error-activating-lv-pve-data-failed-activation-of-logical-volume-pve-data-is-prohibited-while-logical-volume-pve-data_tdata-is-active.106225/
Follow Up #1
03 May 2024
I rebooted another system and had more pains. This time, de-activating t_meta, gave me this:
lvchange -an raid0/raid0_tmeta device-mapper: remove ioctl on (253:4) failed: Device or resource busy Repeat around 20 times device-mapper: remove ioctl on (253:4) failed: Device or resource busy Unable to deactivate raid0-raid0_tmeta (253:4).
The solution was I had to wait a long time, and then things came right!
Follow Up #2
18 May 2024
There is some kind of delay on large magnetic non-RAID drives when you do this procedure. The key will be patience.
Steps:
Did this:
lvchange -an raid0-2/raid0-2_tmeta
Immediate results. Then do did this:
lvchange -an raid0-2/raid0-2_tdata
Wait!
I didn’t, and did this again:
# lvchange -an raid0-2/raid0-2_tmeta
This took really long! Then this error:
Device raid0–2-raid0–2_tmeta (252:4) is used by another device.
But in fact, things were back online and could be seen with lsblk