Table of Contents
Adding a new cluster node
- Copy cluster information from Datacenter / Cluster / Join Information on an existing node in the cluster
- Go to new node and
Join Cluster
Optional. If you’re using GrandWazoo plugin in a cluster, remember to add the new IP address of the node to the firewall, otherwise NAS visibility won’t work. Check the journal if you’re unsure.
Cluster Join Issues
* local node address: cannot use IP ‘192.168.2.2’, not found on local node!
TASK ERROR: Check if node may join a cluster failed!
/etc/hosts for the correct IP addressSetting up SSL
I recommend using CloudFlare’s API for SSL. Once you have this installed, setting up SSL in the cluster is a breeze. Steps:
- Add the DNS name for the node
- Go to the cluster node
- Click System -> Certificates
- Click Add and add the DNS name
- Type is
dnsand plugin iscloudflare
Here is a screenshot when creating the domain:
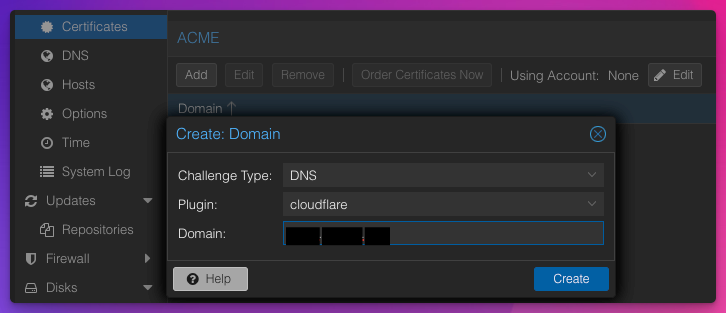
- Next, Order Certificate Now
Here is a screenshot of the order process happening:
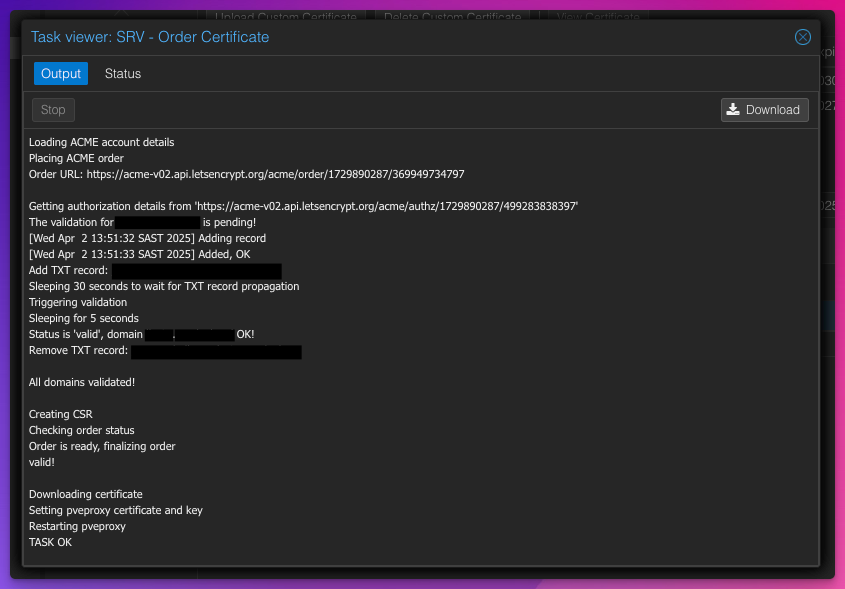
Running a Cluster over a WAN
You shouldn’t. Corosync needs 5 to 10 ms latency and is highly sensitive to jitter. We tried running it over a WAN with 20 milliseconds and you’ll see this in the syslog:
Nov 21 13:26:32 host corosync[2269607]: [TOTEM ] Retransmit List: 94 96 Nov 21 13:26:32 host corosync[2269607]: [TOTEM ] Retransmit List: 94 96 Nov 21 13:26:32 host corosync[2269607]: [TOTEM ] Retransmit List: 94 96 Nov 21 13:26:32 host corosync[2269607]: [TOTEM ] Retransmit List: 94 96 Nov 21 13:26:32 host corosync[2269607]: [TOTEM ] Retransmit List: 94 96 Nov 21 13:26:32 host corosync[2269607]: [TOTEM ] Retransmit List: 98 Nov 21 13:26:33 host corosync[2269607]: [KNET ] link: host: 4 link: 0 is down Nov 21 13:26:33 host corosync[2269607]: [KNET ] host: host: 4 (passive) best link: 0 (pri: 1) Nov 21 13:26:33 host corosync[2269607]: [KNET ] host: host: 4 has no active links Nov 21 13:26:35 host corosync[2269607]: [KNET ] rx: host: 4 link: 0 is up
Unfortunately you now lose a lot of functionality if you have multiple data centres. You’ll loose high availability, migrations between nodes, and possibly the ability to use PBS across one cluster. If our case PBS worked well for a month, but when the cluster became unreliable things broke down miserably.
So yes it’s possible. No, the documentation makes it clear it’s better to have a dedicated network for Corosync which is the underlying synchronization protocol.
Removing Cluster Nodes – still in UI
You need to remove the whole directory /etc/pve/nodes/<nodename>
There are other tricks too, but be careful if it’s name, or ID, or something else. Example:
pvecm status shows the node is gone:
Membership information ---------------------- Nodeid Votes Name 0x00000002 1 a.b.c.1 (local) 0x00000003 1 a.b.c.2 0x00000004 1 a.b.c.3 0x00000005 1 a.b.c.4 0x00000006 1 a.b.c.5 0x00000007 1 a.b.c.6 [email protected]:~# pvecm delnode by_ip_address 400 Parameter verification failed. node: invalid format - value does not look like a valid node name pvecm delnode <node> [email protected]:~# ls /etc/pve/nodes/ name1/ name2/ name3/ name4/ name5/ name6/ deleted-name/ [email protected]:~# pvecm delnode deleted-name Could not kill node (error = CS_ERR_NOT_EXIST) Killing node 1 [email protected]:~# pvecm delnode deleted-name Node/IP: deleted-name is not a known host of the cluster.
Useful Troubleshooting Commands
Change Quorum Quantity
Change quorum quantity (super risky so read about risks first):
pvecm expected X
Status
pvecm status
Deleting a node
Official documentation: https://pve.proxmox.com/wiki/Cluster_Manager#_remove_a_cluster_node
The official documentation clearly states that a node “must be powered off” by removal, but you’ll find these nodes still lingering in your User Interface. That might mean delnode didn’t work properly or you have to refresh your browser.
The command to delete a node is delnode, but when do you do it? There are at least these scenarios:
- The node has died. You will never bring it up again. Perhaps the hardware broke or the hardware was removed or recommissioned.
- The node has died. You’re panicking and you want to bring it up but you’re concerned about your cluster being inconsistent.
- You have properly decommissioned the node, and you’ve switch it off.
- You have properly decommissioned the node, but you haven’t switched it off yet.
In the next section, we’ll only cover #4, the best case scenario.
Properly Decommissioning a Proxmox Cluster Node
As per the documentation:
Log in to a different cluster node (not hp4), and issue a pvecm nodes command to identify the node ID to remove:
Always remember to have IPMI access before taking this action, because, by chance, you might want to switch the host back on. Also note if you commit to this procedure *do not switch on the node again*! This is a one way street, mostly.
Here are the full steps, 1 to 6.
- Ensure the node you want to remove is still on
- Ensure there are no more VMs on the node.
- Log into a different node and do this:
pvecm nodes - Make a note of the node name (3rd column)
- Power down the node you want to remove.
- Do
pvecm delnode name
This documentation refers to the command below, but we couldn’t get it to work:
pvecm delnode hvX Could not kill node (error = CS_ERR_NOT_EXIST) Killing node 3
The documentation refers to names, but you can just use the ID that the pvecm status command gives you. Also make sure you read the official documentation about removing a node.
Upgrading a Cluster
Note 1: You can’t upgrade Proxmox if your cluster isn’t healthy.
Note 2: Multicast versus unicast and knet
We had multicast issues over a WAN and decided to try a switch to Unicast by way of the following switch:
cat /etc/corosync/corosync.conf
...
totem {
cluster_name: cluster
config_version: 7
transport: udpu
interface {
linknumber: 0
}
ip_version: ipv4-6
...
Then during upgrade from 7 to 8, we had this warning:
Checking totem settings.. FAIL: Corosync transport explicitly set to 'udpu' instead of implicit default!
Fixing Corosync.conf
This is tricky because it can be overwritten very quickly and you can easily break the cluster.
Here is the part of the manual that talks about it:
https://pve.proxmox.com/wiki/Cluster_Manager#_corosync_configuration
- You have to make a copy
- You have to work on the copy
- Then make another backup of the main
- Then move the copy over the main
Now that you’re ready for high work, this is it:
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.new edit cp /etc/pve/corosync.conf /etc/pve/corosync.conf.bak mv /etc/pve/corosync.conf.new /etc/pve/corosync.conf
systemctl status corosync.service journalctl -b -u corosync systemctl status pve-cluster.service
Other Caveats
- You probably shouldn’t mix and match Proxmox 7.4 and PBS 8.x.
- It seems you have to trash your VMs when you disjoin the cluster. Well you back them up first, and take them offline, but this is a big problem for most production environments.
Cluster Error about existing virtual machine guests
Joining a Proxmox Cluster is trivial. But what if you can’t? Here are two common errors:
detected the following error(s):
* this host already contains virtual guests
* local node address: cannot use IP ‘192.168.100.2’, not found on local node!
Also please read the official Proxmox material as their documentation is really good:
https://pve.proxmox.com/wiki/Cluster_Manager
- To form a quorum you need at least three nodes
- Changing the hostname and IP is not possible after cluster creation
Once you have this working, you’ll see this output instead of more errors:
Establishing API connection with host '192.168.1.24' Login succeeded. check cluster join API version No cluster network links passed explicitly, fallback to local node IP '192.168.1.21' Request addition of this node
At this point you might see: “Connection error”, but when you go to another node you’ll see this:
Establishing API connection with host '192.168.1.24'
Login succeeded.
check cluster join API version
No cluster network links passed explicitly, fallback to local node IP '192.168.1.21'
Request addition of this node
Join request OK, finishing setup locally
stopping pve-cluster service
backup old database to '/var/lib/pve-cluster/backup/config-1697448355.sql.gz'
waiting for quorum...OK
(re)generate node files
generate new node certificate
merge authorized SSH keys and known hosts
generated new node certificate, restart pveproxy and pvedaemon services
successfully added node 'hypervisor099' to cluster.
TASK OK
Fixing this host already contains virtual guests
You can’t join a cluster when you have existing virtual machines. You have to back them up first and you’ll have to restore them after you’ve joined the cluster.
Important note: If you’ve used the built-in Datacenter => Backup facility of Proxmox you will find after joining the cluster that your backup job confirmation is gone. Simple use the following command line to restore the VMs:
ssh to Proxmox VE host
cd /var/lib/vz/dump qmrestore vzdump-qemu-101-2023_10_16-11_05_33.vma.zst 101 -storage local-lvm
Fixing local node address: cannot use IP ‘a.b.c.d’, not found on local node
This will happen if you’ve changed the IP address of your Proxmox hypervisor.
When changing the IP of the box it seems that you have to manually change the /etc/hosts entry as well:
https://forum.proxmox.com/threads/adding-node-to-cluster-local-node-address-cannot-use-ip-error.57100/
Unable to move a disk on iSCSI TrueNAS Scale to ZFS partition
Undefined freenas_user and/or freenas_password. at /usr/share/perl5/PVE/Storage/LunCmd/FreeNAS.pm line 132. (500)
you can’t move to the same storage with same format (500)
Something to do with RAW storage disks and moving from a remote NAS to a local NAS (both ZFS).